Searching the Physical World: Bridging 3D Models and LMMs
Introduction
Capturing images and video is the first step in digitizing the physical world. Today, techniques such as photogrammetry[1], Neural Radiance Fields (NeRFs)[2], and Gaussian Splatting[3] allow us to transform this raw data into immersive, high-fidelity 3D environments.
High-fidelity 3D reconstruction solves the problem of visualization, but not of understanding. The missing layer is semantics. By integrating Large Multimodal Models (LMMs)—which reason jointly over text and images—we connect language to spatial geometry, enabling natural-language search and localization within 3D environments.
Background: The Semantic Gap in 3D Reconstruction
Digital models have become routine to generate. With a camera and modern reconstruction pipelines, complex environments can be captured and explored in 3D with remarkable realism. Yet despite their visual quality, these models contain minimal semantic information.
3D models are unstructured visual records. While a human can recognize objects in the scene, there is no underlying index to locate equipment, audit inventories, or answer operational questions programmatically. As a result, the practical value of the model is limited.
Today, semantic meaning is typically added through manual tagging. This requires a user to:
- Navigate the virtual space
- Visually identify each asset of interest
- Manually attach labels and metadata
This workflow does not scale. It is time-consuming, error-prone, and static: missed objects remain unsearchable, and any change on-site requires repeating the process. As environments evolve, maintaining an accurate digital record becomes an operational burden.
LMMs provide a structured approach to interpreting physical environments. They support analysis of visual scenes that extends beyond object recognition to include spatial relationships and context, allowing objects to be interpreted in relation to their surroundings.[4][5]
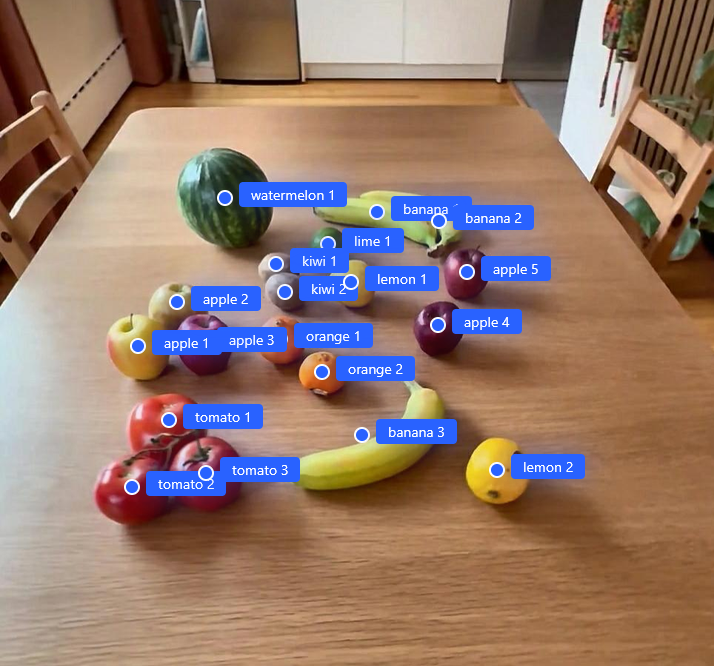
This capability includes precise object localization, identifying the pixel coordinates for each detected element. By recognizing the same object across multiple viewpoints, these models maintain cross-view consistency, distinguishing unique instances from redundant observations. This consistency provides a direct basis for mapping image-level understanding into 3D space.
By leveraging LMMs, we can move beyond manual "point-and-click" labeling. Instead of forcing humans to annotate the model, we allow AI to interpret the site automatically—transforming a passive visual reconstruction into an actionable, searchable asset index.
Innovation: Connecting Language to 3D Space
Our approach decouples semantic reasoning from 3D representation. Rather than attempting to embed meaning directly into 3D geometry, we use 2D imagery as the semantic interface and project the results back into 3D space.
This workflow connects natural language queries to precise 3D locations.
1. Pose Estimation and 3D Reconstruction
We begin by establishing spatial context. Using Structure from Motion (SfM) or Simultaneous Localization and Mapping (SLAM), the system processes raw imagery to recover the position and orientation of every camera frame in a shared coordinate system.

With camera poses defined, we generate the 3D model for visualization. Each image is anchored to a precise location and viewpoint in the model, ensuring that every image pixel can be accurately projected into the reconstructed scene.
2. Semantic Filtering via Vector Embeddings
To make the image collection searchable, every frame is processed through an embedding model, producing a high-dimensional vector representation. This creates a semantic index over the entire image dataset.
When a user issues a query (such as "apple"), the system computes similarity between the text embedding and the image embeddings. This immediately narrows the search to a small subset of frames where the object is likely visible, avoiding the complexity of reasoning directly in 3D.
By extending the query from a single phrase to a list of search terms or a predefined taxonomy, the system evaluates multiple asset classes in parallel. This enables a site-wide semantic scan in a single pass, rather than a sequential, object-by-object inspection.
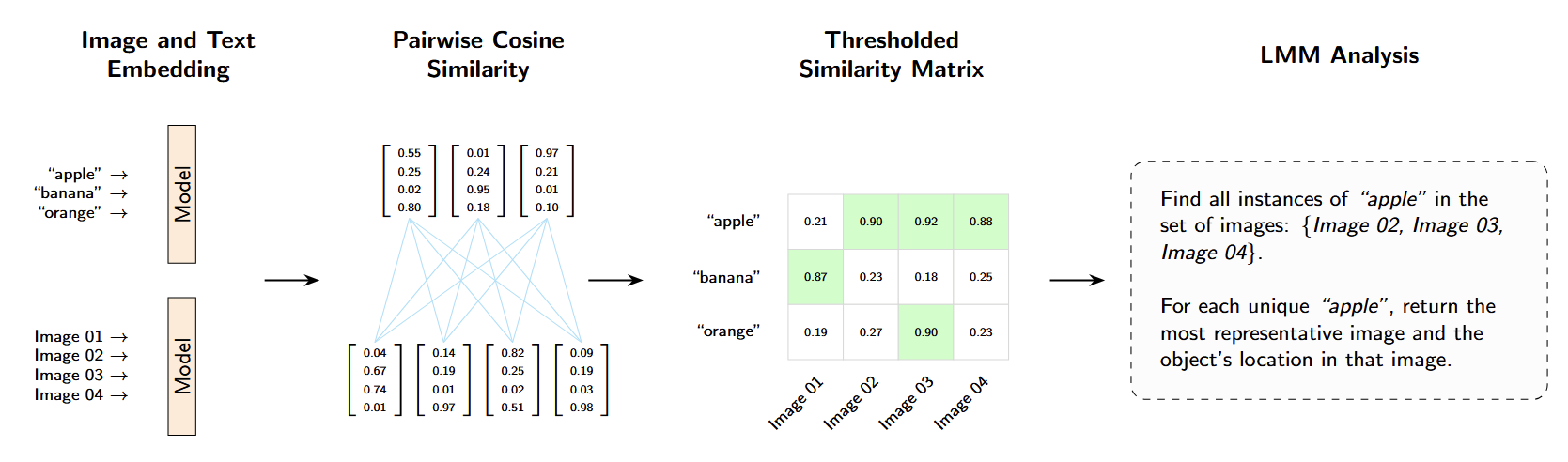
Similarity between image frames and search terms is computed as a cosine similarity matrix over their embeddings. Candidate frames are selected by applying a similarity threshold to reduce the search space. This filtering stage ensures that only frames with a high likelihood of containing relevant assets are forwarded to the multimodal model for analysis, improving computational efficiency and overall system robustness.
3. Multimodal Reasoning and Grounding
The candidate frames are passed to a LMM along with the user's query. By reasoning jointly over text and visual context, the model identifies unique object instances across views, filtering out redundant perspectives and occlusions.
For each instance the model selects a canonical frame, the view with the clearest visual evidence, and produces 2D grounding coordinates corresponding to the object's centroid. At this stage, a natural language request has been translated into a pixel-level reference.
| Search Term | Objects | Images | Pixel Coordinates | Canonical |
|---|---|---|---|---|
| "apple" | apple_1 | image_02 | (324, 187) | True |
| image_03 | (412, 203) | False | ||
| image_04 | (367, 245) | False | ||
| apple_2 | image_03 | (198, 178) | False | |
| image_04 | (289, 156) | True |
4. Spatial Localization in 3D
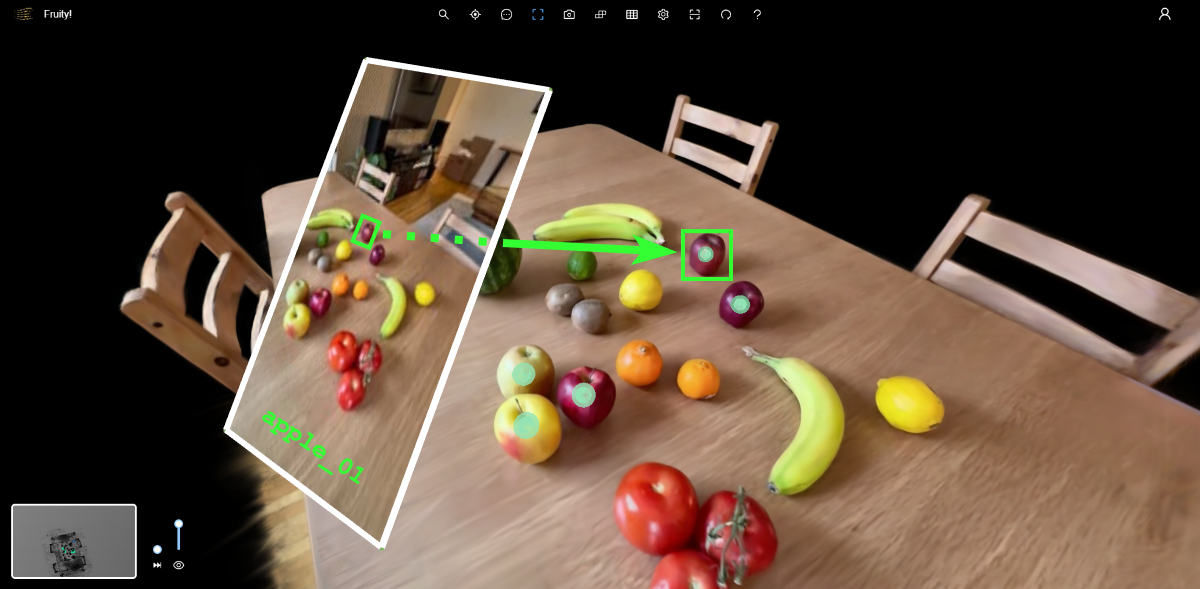
Finally, the 2D coordinates are mapped into 3D space. Using known camera parameters, the system casts rays from the camera center through each identified pixel and computes their intersection with the reconstructed geometry.
This yields a 3D position for each object instance. The system then generates persistent annotations at those locations, creating a spatially grounded asset record within the model.
Impact: From Static Models to Actionable Systems
By coupling 3D reconstruction with semantic reasoning, raw imagery becomes a structured, machine-readable representation of the physical world. This architecture enables several powerful capabilities.
Rapid Inventory and Auditing
What once required days of manual tagging can now be done in minutes. By combining semantic image search with automated localization, a 3D reconstruction becomes an instantly queryable inventory. As new imagery is captured, the process can be rerun to refresh the index, keeping the digital twin synchronized with the real site.
Relational and Contextual Intelligence
Unlike traditional computer vision systems that label objects in isolation, LMMs understand context and relationships. This enables higher-level queries such as identifying assets based on condition, proximity, or orientation. Questions like "find all access panels left open" or "locate equipment within two meters of the primary cooling line" become possible without training bespoke models for each new scenario.
A Spatial Interface for Documentation
Once assets are automatically localized, they become natural anchors for documentation. Maintenance records, inspection histories, and operating manuals can be attached directly to objects in their spatial context, turning the 3D model into a navigable interface for operational knowledge.
Conclusion
Our approach succeeds by utilizing 3D geometry as a spatial index rather than a semantic layer. By maintaining the 2D image dataset as the primary reference for reasoning, we leverage the full density of LMM intelligence where it is most effective. This creates a link between natural language and 3D space, ensuring that our digital twins are not just visually accurate, but programmatically queryable. We have moved from simply digitizing the appearance of a site to indexing its entire spatial reality.
Citations
[1] Hartley, Richard, and Andrew Zisserman. Multiple view geometry in computer vision. Cambridge University Press, 2003. ↩
[2] Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." Communications of the ACM 65.1 (2021): 99-106. ↩
[3] Kerbl, Bernhard, et al. "3D Gaussian splatting for real-time radiance field rendering." ACM Trans. Graph. 42.4 (2023): 139-1. ↩
[4] Doshi, Rohan. "Gemini 3 Pro: The Frontier of Vision AI." The Keyword, Google, 5 Dec. 2025, blog.google/technology/developers/gemini-3-pro-vision/. ↩
[5] "Pointing and 3D Spatial Understanding with Gemini." Google Gemini Cookbook, Google, 2024, colab.research.google.com/github/google-gemini/cookbook/blob/main/examples/Spatial_understanding_3d.ipynb. ↩