From 3D Semantic Search to 3D Object Detection
Summary
Natural language can be used to search reconstructed environments for objects and scenarios[2]. Here, we extend that workflow to recover the full geometry of objects:

The result is a system that converts natural language queries into 3D object instances embedded in a reconstructed scene.
Introduction
In the previous post we showed how natural language queries can be used to localize objects and scenarios inside reconstructed environments. This allowed us to determine whether objects were present, where they appeared, and how many instances existed in the scene. In this article we extend the pipeline to reconstruct object geometry.
Recovering 3D geometry expands the questions we can ask about objects in a scene. Instead of a single point location, we can reason about an object’s size, the volume it occupies, and how it relates to surrounding infrastructure. Once an object’s geometry is reconstructed, we can also augment the scene by automatically removing objects, moving them, or duplicating them.
The key observation is that the semantic search pipeline already provides most of what we need: images that contain the object and an approximate location in space. To recover geometry we extend this pipeline with additional stages that segment the object in each image and combine those silhouettes across views.
In practice, the workflow proceeds as follows. A natural language query retrieves relevant images from the reconstructed scene. A multimodal model then verifies that the object is present in those views and identifies individual object instances. Ray casting estimates the 3D location of each instance. Each image is then segmented to isolate the object, producing a set of silhouettes across camera views. Finally, these silhouettes are combined using multi-view geometry to reconstruct a 3D volume for each detected object.
From Points to 3D Geometry
Once object instances have been identified and their 3D locations established, the next step is to recover their geometry from the available camera views.
We use a prompt-based segmentation model[3] that takes the original natural language query as input to provide a set of masks for each detected object. The projected 3D location is then used to select the most relevant mask from the results, helping to disambiguate between multiple instances.
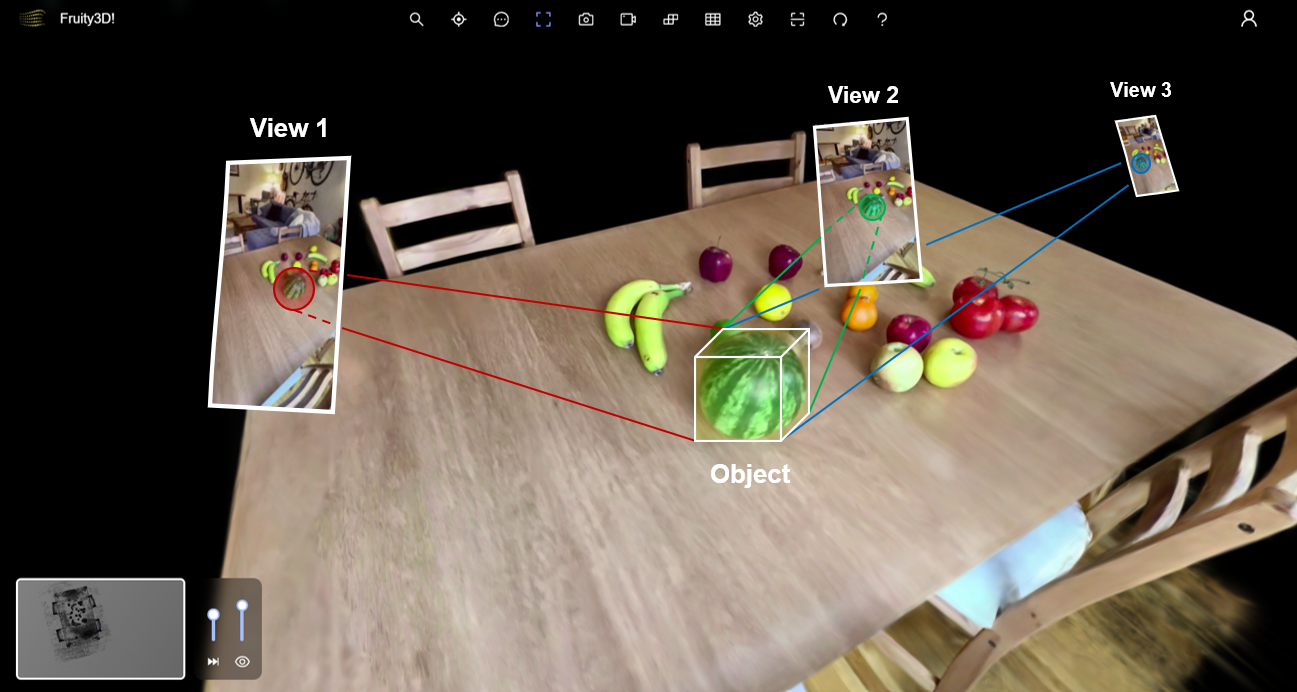
Given camera poses and object masks, each silhouette defines a volume in space where the object could exist. The scene is discretized into voxels, and each voxel is tested against every mask. Voxels that fall outside the silhouette in the majority of views are discarded. The remaining voxels form the visual hull[1] of the object—a volumetric envelope that captures the object’s spatial extent, orientation, and rough geometry.
The voxel volumes for all unique objects can then be converted into optimized meshes and displayed directly in the 3D viewer.
Conclusion
Natural language queries can localize objects within a reconstructed environment. That capability links language to space, allowing users to search a scene in the same way they would search text. These queries can refer to specific objects such as fire extinguishers, as well as broader scenarios such as safety hazards.
In this post we extend that idea from localization to reconstruction. Once an object can be reliably located, its geometry can also be recovered from the same multi-view imagery. This reconstruction describes an object's size, shape, and spatial footprint. The result is a richer representation of the scene. Instead of isolated coordinates, objects become geometric entities that can be measured, analyzed, and manipulated as part of the environment.
Combining semantic search with geometric reconstruction extends our ability to build searchable spatial databases from 3D scans. Instead of manually annotating models, users can query for objects such as fire extinguishers, electrical panels, or safety signage—and the system locates them, verifies them visually, and reconstructs their spatial footprint.
The result is a system that turns raw video into a structured representation of the physical environment—one that can be searched, enhanced, and analyzed.
Citations
[1] Laurentini, Aldo. "The visual hull concept for silhouette-based image understanding." IEEE Transactions on Pattern Analysis and Machine Intelligence 16.2 (1994): 150-162. ↑
[2] Koziol, Conrad and Thomas Charlton. "Searching the Physical World: Bridging 3D Models and LMMs." SpatialView Blog, 20 Jan. 2026, spatialview.io/blog/3d-semantic-search/. ↑
[3] Kirillov, Alexander, et al. "Segment anything." Proceedings of the IEEE/CVF International Conference on Computer Vision (2023): 4015-4026. ↑